
Retrieval-based-Voice-Conversion(RVC)という、新しい音声変換AIを試してみた記録です。
既存のものよりも高速に学習が可能らしい。
ダウンロード
元々は中国語のみでしたが、有志の方が日本語版を配布して下さっています。
ここではRVCのダウンロードから日本語化する方法について解説します。

上のリンクからRVC-beta.7zをダウンロード。
7zはデフォルトでは解凍できません。7-Zip等の解凍ソフトを使って下さい。
解凍後、Cドライブ直下にフォルダを移動します。
日本語化
リンクから緑のCodeボタン→Download zipをクリック。
Zipを解凍後、go-web_jpとinfer-web_jpをRVC-betaのフォルダに移動し、go-web_jpを実行。
正常に起動すると、自動でhttp://127.0.0.1:7865/がブラウザで開きます。
学習データの準備
本記事では、実験としてとあるVtuberの音声を学習させました。
音声からBGMを除去する
雑談動画で学習させようとしましたが、問題となるのがBGMです。
人の声とBGMが被っている場合、学習に悪影響が出る可能性があります。
なので、まずは声とBGMを分離します。
ありがたいことにRVC-WebUIにはBGMの分離機能がついているので、これを利用します。
RVC-betaのフォルダ直下にinputフォルダを作成し、学習データの音声を配置。
ボーカルとインストを分離をクリック。
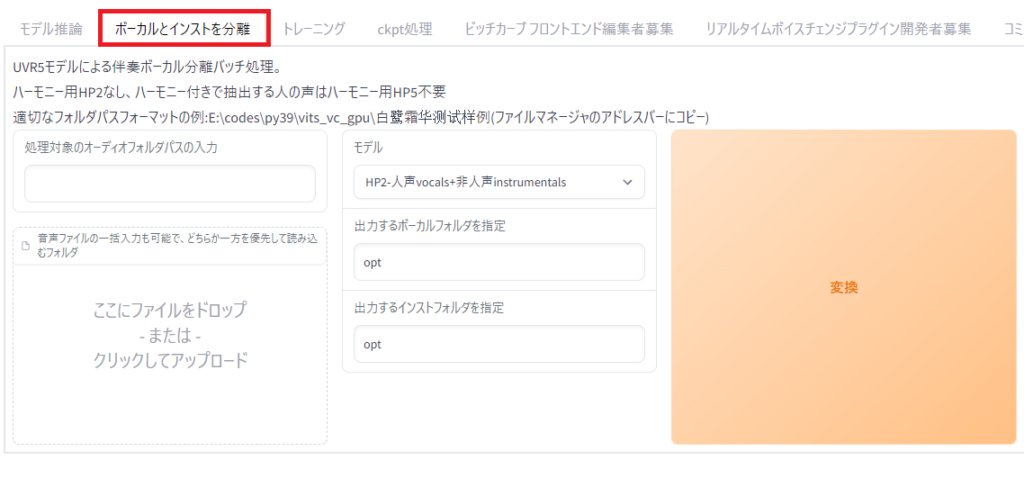
処理対象のオーディオフォルダパスの入力に作成したinputフォルダのパスを入力。
モデルでHP2を選択。
最後に変換をクリックで自動でBGMの除去が行われます。
正常に完了すれば出力するボーカルフォルダ/インストフォルダを指定で入力したフォルダに音声ファイルとBGMファイルが置かれます。(デフォルトはoptフォルダ)
長時間の音声ファイルの変換には時間がかかります。
音声データの切り取りを先に行いましょう。
音声データの切り取り
学習データはただ長時間の音声を突っ込めばいい訳ではなく、発話ごとの音声に切り取る必要があります。
例:
「むかしむかしある所に、おじいさんとおばあさんが住んでいました。おじいさんは山へ芝刈りに、おばあさんは川へ洗濯に行きました。おばあさんが川で洗濯をしていると、ドンブラコ、ドンブラコと、大きな桃が流れてきました。」
これでは長すぎるので、
「むかしむかしある所に、おじいさんとおばあさんが住んでいました。」
「おじいさんは山へ芝刈りに、おばあさんは川へ洗濯に行きました。」
「おばあさんが川で洗濯をしていると、ドンブラコ、ドンブラコと、大きな桃が流れてきました。」
に分けて切り取ります。
また、発話前後の無音部分は可能な限り削除します。
編集はAudacityやSoundEngineなど、適当な音声編集ソフトでOKです。
切り取りが終わったら、RVC-betaのフォルダ直下にtraindataフォルダを作成し、切り取った音声を配置してください。
音声の学習
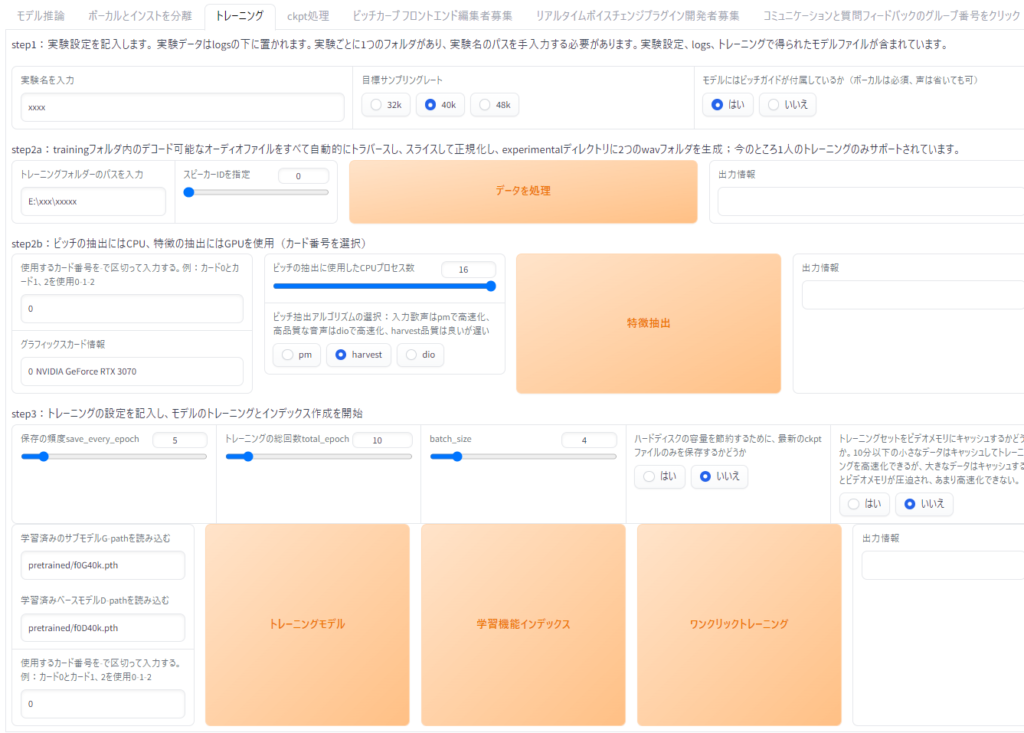
最低限設定が必要な項目のみ記載します。
トレーニングタブをクリック。
実験名を入力に好きな名前を入力。(学習モデルのファイル名になります)
トレーニングフォルダーのパスを入力に先ほど作成したtraindataフォルダのパスを入力。
トレーニングの総回数total_epochを好きな値に設定。初めはデフォルトで行い、精度を上げたい場合は値を増やすと良いです。
設定後、右下のワンクリックトレーニングをクリックで学習が開始。
学習したモデルはweightsフォルダに出力されます。
私の環境だとワンクリックトレーニングを実行時に一度エラーが起きました。
その場合は以下の順番でボタンを押してください。
- データを処理
- 特徴抽出
- 学習機能インデックス
- トレーニングモデル
- ワンクリックトレーニング(4.でエラーが起きる場合)
推論
学習したモデルを使い、音声を変換します。
モデル推論タブに移動。
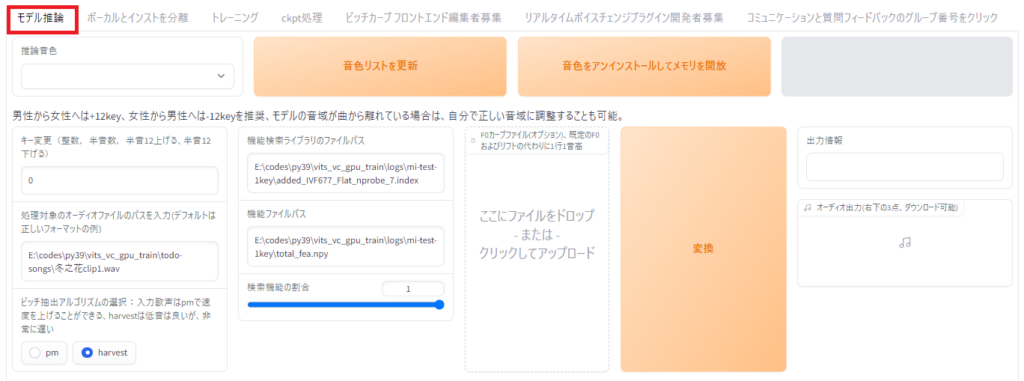
音色リストを更新ボタンをクリックし、推論音色から学習したモデルを選択。
処理対象のオーディオファイルのパスを入力に変換したい音声のパスを入力。
機能検索ライブラリのファイルパスに、logフォルダ内にある学習モデルのadded_~.indexを入力。
機能ファイルパスに、logフォルダ内にある学習モデルのtotal_fea.npyを入力。
ピッチ抽出アルゴリズムの選択は好きな方を選択し、変換をクリック。
正常に変換が終わると、出力情報がSuccessになり、その下に変換した音声が表示されます。


コメント