
本記事では、自分の好きなキャラを追加学習できる「DreamBooth」をRunPod上で行うやり方について紹介します。
DreamBoothの詳細については省きますのであしからず。
アカウント作成
SignUpからRunPodアカウントを新規作成し、ログイン。
ログイン後、マイページを開く。
資金の追加
マイページのMANAGEからBillingをクリック。
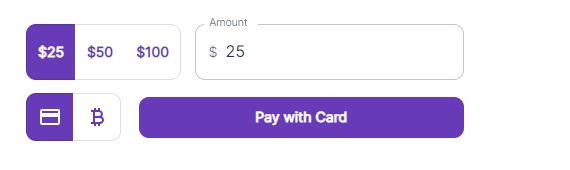
追加したい金額を選択し(入力も可能)、支払い方法を選択後クリック。
支払い画面に飛ぶのでカード番号等を入力し支払い。
10$もあれば十分に学習出来ます。
学習画像の準備
DreamBoothの学習は5~6枚の画像でも十分ですが、50枚や100枚の方がいい結果が出たという話も聞きます。
ですので最適な枚数は分かりませんが、経験上10枚はあった方が良い気がします。
学習画像を用意したら、512×512にリサイズする必要があります。
手作業でリサイズしてもいいですが、キャラクターや人物画像であればIzumi SatoshiさんのColabがオススメです。
GPUの準備
マイページのCLOUDからSecure Cloudを選択。
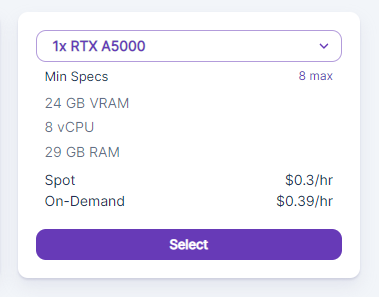
RTX A5000を選択。
コンテナディスクはそのまま、ボリュームディスクは多めにする。(今回は50GB)
テンプレートはRunPod Pytorchを選択しContinue。
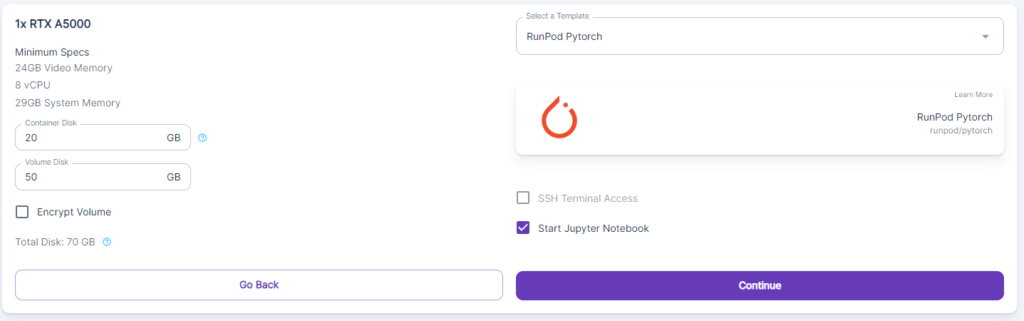
設定を確認し、Deploy On-Demandをクリック。

これでGPUの準備は完了です。
My Podsを選択。
More Actionsアイコン(下画像参照)から、Edit Podを選択。
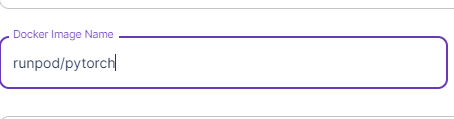
Docker Image Nameにrunpod/pytorchと入力し、Save。
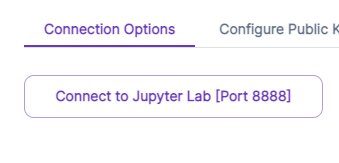
Podの再起動後、Connect > Connect to Jupyter Labをクリック
Jupyter Labが起動したらOKです。
モデルの準備
Python3(Notebook)をクリック。

セルに下のコマンドを張り付けて実行。
Dreamboothのリポジトリがクローンされます。
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.git
クローンされたリポジトリをクリックし、dreambooth_runpod_joepenna.ipynbに入る。

2番目のセルを実行
モデルをダウンロードする場合
次にモデルのダウンロードを行います。(自前の.ckptファイルを使いたい人はこちら)
HUGGING_FACE_API_TOKEN_HEREを自分のトークンに置き換え、セルを実行。
(HuggingFaceへ未登録の方は登録後、トークンページからトークンが取得できます)
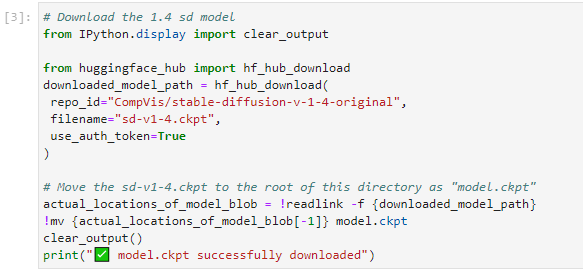
次のセルを実行し、HuggingFaceからダウンロード。
デフォルトではSD1.5がダウンロードされます。他モデルを使いたい場合はrepo_idをHuggingFace上のモデル名に、filenameをckptファイル名に変更してください。
例:WaifuDiffusion1.3を使用する場合はrepo_idをhakurei/waifu-diffusion-v1-3、filenameをwd-v1-3-full.ckptに変更。
自前のckptファイルを使う場合
ckptファイルをドラッグアンドドロップし、model.ckptにリネーム。
HuggingFace以降のセルは必要ないのでRegularization Imagesに進んでください。
学習の実行
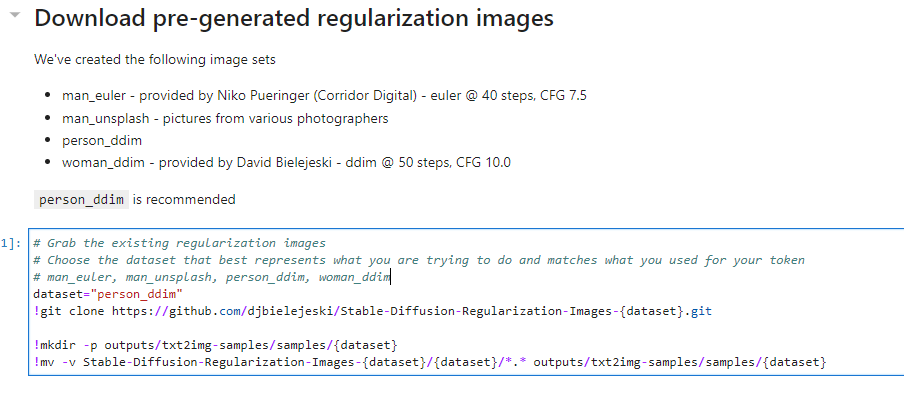
Download pre-generated regularization imagesのセルを実行。
training_imagesフォルダを作成し、そこに用意しておいた学習用画像をアップロード。

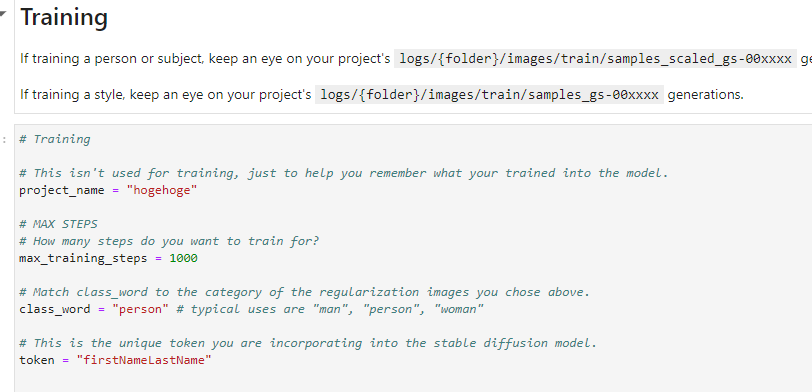
Trainingセルに移動。
project_nameに好きなプロジェクト名。
max_training_stepsに学習させたいステップ数。(目安は学習画像 x 100~300)
tokenに好きなトークン名を入力。
ここに入力したトークン名+personで呼び出します。例えばsksを入れた場合
sks person, portrait photograph, 85mm medium format photo
などで生成することになります。
入力したらTrainingセルを実行。学習が開始されるので終わるまで待ちます。

Training complete.と表示されたら終了です。
学習したモデルのダウンロード
Copy and name the checkpoint fileを実行。
training_modelsフォルダに学習したモデルがコピーされるので、右クリック > Downloadでダウンロード。
GPUの終了
マイページ > My PodsからGPUの停止ボタンを押す。
Stop Podをクリック。
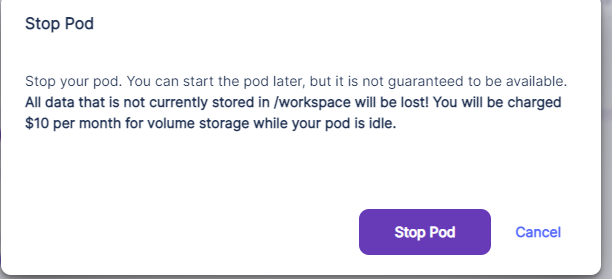
この時点では完全に終了していないので注意。
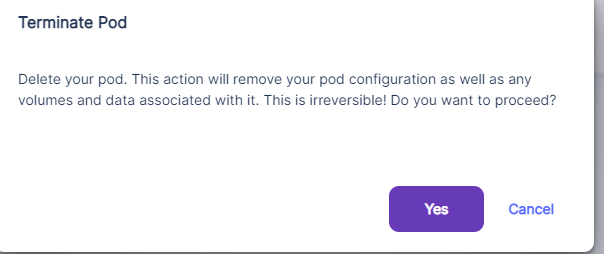
ゴミ箱マークをクリック。
Terminate Podの表示が出るのでYes。
My Podsから表示が消えたら完了です。お疲れさまでした。


コメント
はじめまして
この記事を参考にトライさせていただいたのですが
trainingを実行すると
NameError: name ‘trainer’ is not defined
と表示されてしまいます…
コメントありがとうございます。
モデルは何を使用されていますか?
当記事で紹介しているプログラムは、SD1.4の頃に書かれたものであり、仕様が変更されたver2.0以上では実行できないようです。
ファインチューンモデルについても、ベースが2.0以上であれば同様と思われます。
Githubにも同じようなエラー報告があるため、その内修正されるかもしれません。
1/23日時点でSD1.5で実行可能であることは確認済みです。参考になれば幸いです。
すみません解決しました!!
学習させるためのモデルがfp16ではなかったため学習できなかったようです…